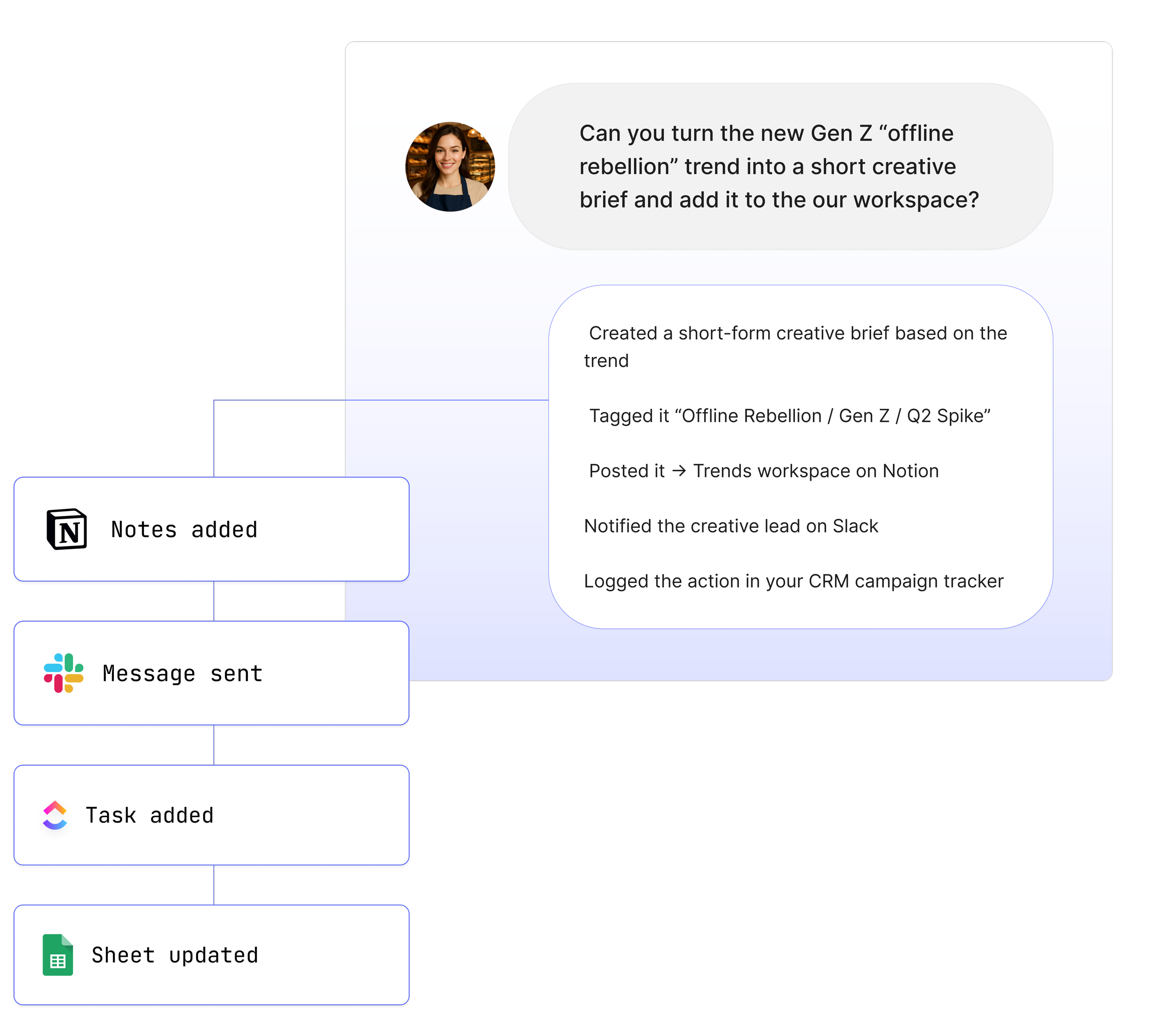
Mistral at Maybe*
Fast responses, multilingual support, and cost effective AI when scale matters.
Maybe* uses multiple large language models behind the scenes. Our orchestration Agent selects the best one for each task. Mistral is one of the models we rely on when your work needs quick responses, strong European language support, efficient code generation, or cost effective performance at scale.
You do not need to choose Mistral yourself. When your Agent sees a task that fits Mistral’s strengths, it will route the request there automatically.
How Maybe* Uses Mistral
Mistral is often chosen when your Agent needs to:
Respond quickly with low latency
Process high-volume tasks efficiently
Support translation or multilingual work across European languages
Generate or update code with minimal overhead
Provide a cost-effective option when speed matters more than depth
Run lightweight tasks that do not require long context or heavy reasoning
From your perspective, nothing changes. You still work in Slack, Teams, or your usual tools and say things like:
“@Maybe translate this into French and highlight the key points.”
“@Maybe generate a quick code example for this function.”
“@Maybe process this list and prepare it for our workflow.”
Behind the scenes, the orchestration Agent may choose Mistral to handle that work.
Where Mistral Shines
Speed and efficiency
Fast inference across model sizes
Low latency for real-time tasks
Efficient token processing for high throughput
Use it for: rapid-fire tasks, real-time assistants, quick summaries, and fast transformations.
Multilingual capability
Excellent support for European languages
Strong performance in French, German, Spanish, and Italian
Good at translation and cross-lingual rewriting
Use it for: localisation workflows, translation requests, and multi-region operations.
Code generation
Codestral model built specifically for coding tasks
Strong at code completion and structured generation
Helpful for multiple programming languages
Use it for: boilerplate code, helper functions, explanations, and small refactors.
Open source flexibility
Several models available for self-hosting
More control over data and privacy
No dependency on external APIs if required
Use it for: regulated environments, private deployments, and custom infrastructure.
Customisation and fine-tuning
Models that can be fine-tuned for specific use cases
Adaptable to domain-specific datasets
Flexible deployment options
Use it for: proprietary terminology, industry-specific tasks, internal knowledge work.
Lightweight deployment
Smaller models suitable for edge or on-device use
Lower compute requirements
Good for latency-sensitive applications
Use it for: mobile workflows, embedded devices, IoT, low low-resource environments.
Function calling
Native support for tool use and structured outputs
Reliable function calling for agent workflows
Clean integration with Maybe* Agents
Use it for: API calls, structured outputs, form filling, and task orchestration.
Specialised strengths
Mistral stands out in the areas where speed, cost efficiency, and multilingual capability matter most.
It is particularly strong at delivering quick responses with low latency, making it ideal for teams that rely on real-time support or need to process large volumes of data efficiently. When your team needs immediate answers or lightweight transformations, Mistral helps your Agent work smoothly and responsively.
Mistral is also skilled at handling European languages.
It performs well in French, Spanish, German, Italian, and others, making it valuable for teams that operate across multiple regions or support multilingual customers. It can translate, summarise, or transform text in a natural and fluent way.
When the work involves generating or modifying code, Mistral’s Codestral model provides strong and reliable support.
It produces clean, structured snippets and helpful explanations, allowing your team to move quickly without sacrificing clarity.
It also shines in environments where computing resources are limited.
Mistral’s smaller models can run on lower-cost hardware or private infrastructure, giving organisations flexibility in how they deploy AI internally.
These strengths become even more useful when paired with other tools. Your Agent can use Mistral to handle fast processing or translation tasks, then pass the results into Google Docs, Sheets, Slack, Teams, ClickUp, Notion, or other systems. Work flows efficiently from request to result without manual effort.
How Mistral Works With Other Models
Mistral does not work alone inside Maybe*. It is one of several models your Agent can choose from. The orchestration layer watches the task you give it and decides which model is the best fit. Mistral is often selected when the work needs speed, multilingual fluency, or efficient processing rather than deep reasoning.
Your Agent can also use Mistral as a fast fallback model. For simple or high-volume tasks, Mistral can handle the work quickly so other models are reserved for more complex requests.
Sometimes, careful reasoning is important. Sometimes speed matters more. Mistral is chosen for the latter. When the request needs quick output or efficient throughput, your Agent routes the work to Mistral automatically.
From your perspective the process stays simple. You speak to @Maybe in Slack, Teams, or your workspace. You do not choose the model. You do not manage prompts. Maybe* selects Mistral when it is the right tool for the job and handles everything behind the scenes.
See How Teams Like Yours Are Using Maybe* Integrations



About Maybe*
Maybe* connects to the systems your team relies on every day so AI can handle real work end to end. Use Maybe* directly, or from Slack or Microsoft Teams. Wherever you work, our AI Agents bring the right context, take the right actions, and keep workflows moving.
Powered by our patent pending AI Agent Builder and orchestration layer, Maybe* chooses the right model and the right integration for each task. You do not need to configure prompts per model or build complex routing.
Begin with a single AI Agent and a few key tools. Add more models and integrations as you grow. Maybe* expands from simple automations to fully orchestrated, cross tool workflows.